Информатика -- наука, изучающая общие свойства информации, процессы ее хранения и обработки, методы создания информационных систем и технологий. Виды информационных процессов: создание новой информации, преобразование, уничтожение и передача информации.
Информатика изучает: 1) устройство ЭВМ, технические средства, используемые для обработки информации; 2) алгоритмические средства, алгоритмы решения различных задач; 3) программные средства, програмное обеспечение ЭВМ. Информатика -- это: 1) отрасль народного хозяйства (создание технических и программных средств); 2) фундаментальная наука (методология и теория создания информационных систем и технологий); 3) прикладная дисциплина (изучение информационных процессов, разработка информационных моделей, систем и технологий).
Задачи информатики: 1) исследование информационных процессов любой природы; 2) разработка информационной техники и создание новейшей технологии переработки информации; 3) использование компьютерной техники и технологии во всех сферах общественной жизни.
Информационное общество -- общество, в котором большинство людей заняты производством, хранением, переработкой и реализацией информации. Критерии развитости: наличие компьютеров, развитие рынка программного обеспечения, функционирование компьютерных сетей. Информационная культура -- умение работать с информацией, используя для ее получения, обработки и передачи компьютерную технологию, современные технические средства и методы.
Информационная революция -- качественные изменения в методах обработки информации, приводящие к преобразованию общественных отношений. В истории человеческого общества произошло несколько информационных революций: 1) изобретение письменности (передача знаний от поколения к поколениям); 2) изобретение книгопечатания, (изменило индустриальное общество, культуру, организацию деятельности); 3) изобретение телеграфа, телефона, радио, телевидения (позволило оперативно передавать информацию); 4) изобретение микропроцессорной технологии и ЭВМ (создание компьютеров, компьютерных сетей).
Развитие вычислительной техники начинается с первой счетной машины Паскаля (1642 г.), суммирующей десятичные числа. Машина Лейбница (1673 г.) выполняла все четыре арифметических действия. Она стала прототипом арифмометров (1820-1960 гг.) Идея создания программно-управляемой счетной машины, имеющей арифметическое устройство, устройство управления, устройства ввода информации и печати, была выдвинута Бэббиджем (1822 г.).
Изобретение электронных ламп, транзисторов, интегральных схем (ИС) предопределили появление и развитие ЭВМ. Поколения ЭВМ:
1 поколение (1951-1954): электронные лампы, ОЗУ на ЭЛТ,
емкость ОЗУ 100 байт, быстродействие ![]() оп/с, пульт
управления и перфокарты.
оп/с, пульт
управления и перфокарты.
2 поколение (1958-1960): транзисторы, ОЗУ на ферритовых сердечниках,
емкость ОЗУ 1000 байт, быстродействие ![]() оп/с, перфокарты и перфоленты.
оп/с, перфокарты и перфоленты.
3 поколение (1965-1976): интегральные схемы (ИС), ОЗУ на ферритовых
сердечниках, емкость ОЗУ ![]() байт, быстродействие
байт, быстродействие ![]() оп/с,
для ввода и вывода информации используется алфавитно-цифровой терминал.
оп/с,
для ввода и вывода информации используется алфавитно-цифровой терминал.
4 поколение (1976-1985): большие и сверхбольшие ИС, ОЗУ на БИС и СБИС,
емкость ОЗУ -- ![]() байт, быстродействие --
байт, быстродействие -- ![]() оп/с,
монохроматический и цветной графический дисплей, клавиатура, мышь и др.
оп/с,
монохроматический и цветной графический дисплей, клавиатура, мышь и др.
5 поколение (1986- ... ): опто- и криоэлектроника, ОЗУ на СБИС, емкость ОЗУ
![]() байт, быстродействие
байт, быстродействие ![]() оп/с,
цветной дисплей, клавиатура, мышь, мультимедиа, устройство
голосовой связи с ЭВМ и др.
оп/с,
цветной дисплей, клавиатура, мышь, мультимедиа, устройство
голосовой связи с ЭВМ и др.
1. ИНФОРМАЦИЯ И ЕЕ КОДИРОВАНИЕ
1.1. Информация и ее свойства. Датчик, измеряющий физическую величину, создает электрический сигнал. Данные -- это зарегистрированные сигналы. Методы регистрации: перемещение тел, изменение формы, поверхности, электрических, магнитных и оптических характеристик носителя информации, изменение состояния электронной системы и т.д. Основные операции с данными: сбор, формализация, фильтрация, сортировка, архивация, защита, передача, преобразование.
Пусть выход датчика в зависимости от измеряемой величины может принимать
![]() различных состояний. Каждый акт измерения является опытом с
различных состояний. Каждый акт измерения является опытом с ![]() исходами,
результат которого заранее неопределен. Аналогично, при формировании
сообщения каждый символ выбирается из алфавита, содержащего
исходами,
результат которого заранее неопределен. Аналогично, при формировании
сообщения каждый символ выбирается из алфавита, содержащего ![]() букв, что
может рассматриваться как опыт с
букв, что
может рассматриваться как опыт с ![]() исходами.
исходами.
Проведение опыта (получение сообщения) снижает неопределенность наших
знаний об объекте. Если опыт имеет ![]() исходов, то
мерой неопределенности является функция
исходов, то
мерой неопределенности является функция ![]() , зависящая от числа
исходов. Если
, зависящая от числа
исходов. Если ![]() , то неопределенность отсутствует и
, то неопределенность отсутствует и
![]() , с ростом
, с ростом ![]() функция
функция ![]() возрастает. Рассмотрим два
независимых опыта
возрастает. Рассмотрим два
независимых опыта ![]() и
и ![]() с числом равновероятных исходов
с числом равновероятных исходов
![]() и
и ![]() Сложный опыт, состоящий в одновременном выполнении
опытов
Сложный опыт, состоящий в одновременном выполнении
опытов ![]() и
и ![]() имеет
имеет
![]() равновероятных исходов
(то же самое относится к сообщению из двух символов). Итак, мера неопределенности
сложного опыта должна быть равна сумме мер неопределенностей опытов
равновероятных исходов
(то же самое относится к сообщению из двух символов). Итак, мера неопределенности
сложного опыта должна быть равна сумме мер неопределенностей опытов
![]() и
и ![]() :
:
![]() .
Перечисленным требованиям удовлетворяет функция
.
Перечисленным требованиям удовлетворяет функция
![]() которая
называется энтропией. Если
которая
называется энтропией. Если ![]() то единицей измерения является бит, (binary digit) если
то единицей измерения является бит, (binary digit) если
![]() то дит.
то дит.
В опыте, имеющем ![]() равновероятных исходов, вероятность каждого из них
равновероятных исходов, вероятность каждого из них
![]() На долю каждого из
На долю каждого из ![]() исходов приходится энтропия
исходов приходится энтропия
![]() .
Найдем количество информации, получаемой при выборе одного из
двух равновероятных исходов:
.
Найдем количество информации, получаемой при выборе одного из
двух равновероятных исходов:
![]() (бит).
(бит).
Энтропия опыта с ![]() неравновероятными исходами определяется
формулой Шеннона (1948 г.):
неравновероятными исходами определяется
формулой Шеннона (1948 г.):
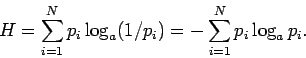
Пусть до получения информации имеются некоторые
предварительные сведения об объекте ![]() .
Мерой нашей неосведомленности является функция
.
Мерой нашей неосведомленности является функция
![]() , которая в то же время служит и мерой
неопределенности состояния объекта. После получения
некоторого сообщения
, которая в то же время служит и мерой
неопределенности состояния объекта. После получения
некоторого сообщения ![]() получатель приобрел некоторую
дополнительную информацию
получатель приобрел некоторую
дополнительную информацию
![]() , уменьшившую
его априорную неосведомленность так, что апостериорная
(после получения сообщения
, уменьшившую
его априорную неосведомленность так, что апостериорная
(после получения сообщения ![]() ) неопределенность состояния объекта
стала
) неопределенность состояния объекта
стала
![]() .
.
Тогда количество информации
![]() об объекте,
полученной в сообщении
об объекте,
полученной в сообщении ![]() , определяется так:
, определяется так:
![]() то есть количество информации равно уменьшению неопределенности
состояния системы (убыли энтропии).
то есть количество информации равно уменьшению неопределенности
состояния системы (убыли энтропии).
Если после сообщения неопределенность обратилась в ноль
![]() ), то первоначальное неполное знание заменится
полным знанием и количество информации в сообщении равно начальной энтропии
), то первоначальное неполное знание заменится
полным знанием и количество информации в сообщении равно начальной энтропии
![]() Иными словами, энтропия
объекта
Иными словами, энтропия
объекта ![]() может рассматриваться как мера
недостающей информации.
может рассматриваться как мера
недостающей информации.
Свойства информации (энтропии): 1) информация (энтропия) сложного опыта (сообщения) равна сумме информаций (энтропий) его частей; 2) при том же числе исходов наибольшую информацию (энтропию) имеет опыт (сообщение) с равновероятными исходами. Требования к информации: достоверность, полнота, актуальность, полезность, понятность, адекватность.
1.2. Метод измерения информации.
Рассмотрим алфавит из ![]() символов, где
символов, где ![]() (
(![]() ) -- вероятность выбора из алфавита
) -- вероятность выбора из алфавита ![]() ой
буквы для кодирования сообщения. Каждый такой выбор уменьшает степень
неопределенности сообщения, увеличивая
количество информации. Среднее количество информации,
сообщаемое при выборе одного символа, согласно формуле Шеннона, равно:
ой
буквы для кодирования сообщения. Каждый такой выбор уменьшает степень
неопределенности сообщения, увеличивая
количество информации. Среднее количество информации,
сообщаемое при выборе одного символа, согласно формуле Шеннона, равно:
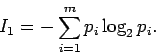
Если выбор каждой буквы равновероятен, то ![]() Подставляя
это значение, получим, что каждый символ несет информацию:
Подставляя
это значение, получим, что каждый символ несет информацию:
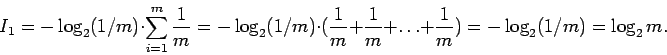
В ЭВМ информация кодируется числовыми кодами. Если система счисления
имеет основание ![]() , то числу разрядов
, то числу разрядов ![]() соответствует разное количество
соответствует разное количество
![]() комбинаций цифр (
комбинаций цифр (![]() ). Если
). Если ![]() то
то
![]() то есть в 4 разрядах может быть записано
то есть в 4 разрядах может быть записано
![]() бит.
бит.
При представлении информации в виде последовательности
символов 0 и 1, раскодирование возможно при наличии
соглашения о фиксированной
длине последовательностей из 0 и 1, составляющих слово. Такой
длиной принято считать восемь символов (0 и 1) -- 8 бит или байт.
Более крупные единицы:
1 Кбайт=1024 байта=![]() байт, 1 Мбайт=1024 Кбайта=
байт, 1 Мбайт=1024 Кбайта=![]() байт,
байт,
1 Гбайт=1024 Мбайта=![]() байт, 1 Тбайт=1024 Гбайта=
байт, 1 Тбайт=1024 Гбайта=![]() байт
байт
(![]() ).
).
В восьми разрядах (байте) можно записать 256 различных целых двоичных чисел, что достаточно чтобы дать неповторяющееся обозначение каждой заглавной и строчной букве русского и английского алфавитов, цифрам, знакам препинания, всем символам на клавиатуре компьютера. Таблица кодирования символов 8-битовыми числами называется кодовой таблицей символов ASCII (American Standart Code for Information Interchange), она представлена на обложке.
1.3. Системы счисления. Информация в ЭВМ кодируется в двоичной, двоично-десятичной или в шестнадцатиричной системе счисления. Система счисления -- это способ наименования и изображения чисел с помощью цифр, то есть символов, имеющих определенные количественные значения.
В позиционной системе счисления количественное значение каждой цифры
зависит от ее места (позиции) в числе.
Количество ![]() различных цифр, используемых для
изображения числа в позиционной системе счисления,
называется основанием системы счисления. Значения цифр лежат
в пределах от 0 до
различных цифр, используемых для
изображения числа в позиционной системе счисления,
называется основанием системы счисления. Значения цифр лежат
в пределах от 0 до ![]() Числа в системе счисления с
основанием
Числа в системе счисления с
основанием ![]() равны:
равны:
Максимальное целое число, которое может быть представлено в
![]() разрядах:
разрядах:
![]() Минимальное значащее (не
равное 0) число, которое можно записать в
Минимальное значащее (не
равное 0) число, которое можно записать в ![]() разрядах
дробной части:
разрядах
дробной части:
![]() Имея в целой части числа
Имея в целой части числа ![]() , а в дробной
, а в дробной ![]() разрядов,
можно записать всего
разрядов,
можно записать всего ![]() разрядных чисел.
Диапазон значащих чисел
разрядных чисел.
Диапазон значащих чисел ![]() в системе счисления
с основанием
в системе счисления
с основанием ![]() при наличии
при наличии ![]() разрядов в целой части и
разрядов в целой части и
![]() разрядов в дробной части (без учета знака числа) будет:
разрядов в дробной части (без учета знака числа) будет:
![]() При
При
![]() имеем:
имеем:
![]()
Чем больше основание ![]() тем больше затраты на изображение
цифры, но меньше разрядов требуется для изображения одного
и того же числа. Наиболее эффективной является использование
троичной системы счисления.
тем больше затраты на изображение
цифры, но меньше разрядов требуется для изображения одного
и того же числа. Наиболее эффективной является использование
троичной системы счисления.
Десятичная система счисления (![]() ) используется при ручном счете.
) используется при ручном счете.
![]()
Таблица двоичных кодов десятичных и шестнадцатеричных цифр.
| DEC | BIN | HEX | DEC | BIN | HEX | DEC | BIN | HEX | DEC | BIN | HEX |
| 0 | 0000 | 0 | 4 | 0100 | 4 | 8 | 1000 | 8 | 12 | 1100 | C |
| 1 | 0001 | 1 | 5 | 0101 | 5 | 9 | 1001 | 9 | 13 | 1101 | D |
| 2 | 0010 | 2 | 6 | 0110 | 6 | 10 | 1010 | A | 14 | 1110 | E |
| 3 | 0011 | 3 | 7 | 0111 | 7 | 11 | 1011 | B | 15 | 1111 | F |
Шестнадцатиричная система счисления -- основание ![]() Используются цифры от 0 до 9 и буквы
Используются цифры от 0 до 9 и буквы ![]() =10,
=10, ![]() =11,
=11, ![]() =12,
=12,
![]() =13,
=13, ![]() =14,
=14, ![]() =15. Восемь двоичных разрядов (байт) могут
быть представлены
только двумя шестнадцатиричными разрядами (1 байт = 8 битов,
то есть
=15. Восемь двоичных разрядов (байт) могут
быть представлены
только двумя шестнадцатиричными разрядами (1 байт = 8 битов,
то есть
![]() комбинаций).
комбинаций).
Двоично-десятичное представление -- представление десятичного числа при котором каждая цифра отдельно кодируются четырьмя двоичными цифрами и в таком виде записываются последовательно друг за другом. Двоично-десятичная запись более длинная, но в ней удобнее производить арифметические действия и выводить числа на экран.
Пример:
1) Перевод двоичного числа в десятичное:
![]() 2) Перевод шестнадцатиричного числа в двоичное:
2) Перевод шестнадцатиричного числа в двоичное:
![]() 3) Перевод десятичного числа в двоично-десятичное:
3) Перевод десятичного числа в двоично-десятичное:
![]()
1.4. Кодирование целых положительных чисел.
Кодирование -- преобразование состояния ![]() системы
в сообщение
системы
в сообщение ![]() посредством некоторого оператора
посредством некоторого оператора ![]() :
:
![]() , где
, где
![]()
![]() -- конечные множества состояний системы
и соответствующих им сообщений (знаков в алфавите).
-- конечные множества состояний системы
и соответствующих им сообщений (знаков в алфавите).
Система кодирования -- правила кодового обозначения объектов, используемые для удобной и эффективной обработки информации. Вся информация (данные и команды) представлена в виде двоичных кодов. Ячейка памяти ОЗУ, к которой можно обратиться, имеет длину 1 байт. Каждый байт ОЗУ имеет свой адрес. Поле -- последовательность битов в определенном формате, имеющая некоторый смысл. Машинное слово -- наибольшая последовательность разрядов (бит), которую ЭВМ может обрабатывать как единое целое. Его длина зависит от разрядности процессора (16, 32, 64 бита). Различают слово, полуслово, двойное слово.
Если длина машинного слова 16 бит, то наибольшее целое число,
которое может быть в них записано равно
![]() ,
а наименьшее -- 0. В языке Pascal такие числа определены как Word.
Числа типа Longint занимают в памяти ЭВМ 4 байта.
,
а наименьшее -- 0. В языке Pascal такие числа определены как Word.
Числа типа Longint занимают в памяти ЭВМ 4 байта.
Сложение и умножение производятся по правилам:
1.5. Кодирование целых чисел со знаком.
Прямой код
двоичного числа включает в себя код знака (знак ![]() соответствует 0, знак
соответствует 0, знак ![]() - 1)
и абсолютное значение этого числа:
- 1)
и абсолютное значение этого числа:
Обратный код положительных чисел такой же как и прямой код,
в знаковом разряде -- 0.
Для получения обратного кода отрицательного числа его разряды
инвертируются (0 заменяется на 1 и наоборот), в знаковом разряде
-- цифра 1:
Дополнительный код положительных чисел такой же как и прямой код.
У отрицательных чисел дополнительный код равен результату суммирования
обратного кода числа с единицей младшего разряда:
В ЭВМ разность ![]() находится так: оба числа переводятся
в дополнительный код, затем складываются и единица в самом
старшем разряде отбрасывается. То есть вычитание сводится
к сложению, осуществляемому с помощью сумматора.
находится так: оба числа переводятся
в дополнительный код, затем складываются и единица в самом
старшем разряде отбрасывается. То есть вычитание сводится
к сложению, осуществляемому с помощью сумматора.
К этому же результату можно прийти иначе: сместим положение нуля на середину
интервала 0 - 65535 и будем считать, что числа из первой половины
0-32767 положительные, а числа из второй половины 32769 - 65535
отрицательные. Тогда
![]() -- код
отрицательного числа, а
-- код
отрицательного числа, а
![]() -- код положительного
числа. Это соответствует типу Integer на языке Pascal,
при размещении чисел из интервала [-32768;32767] в 2 байтном машинном слове.
-- код положительного
числа. Это соответствует типу Integer на языке Pascal,
при размещении чисел из интервала [-32768;32767] в 2 байтном машинном слове.
Пример. Рассмотрим операции 6+7=13, 14-8=6, 5*3=15, 12:4=3
в двоичных числах. Например, в десятичной системе: 5-3=2. Дополнительный
код для 3 равен 7 (3+7=10). Так как 5+7=12, то отбрасывая старший разряд
получаем 2. Тот же пример в двоичной системе: 0101-0011=0010; дополнительный
код для 0011 равен 1101 (0011+1101=1 0000). Итак 0101+1101=10010. Старший
разряд отбрасывается, получается ![]() .
.
1.6. Кодирование действительных чисел. Так как в ЭВМ для записи числа отводится конечное число разрядов, то количество возможных значений записываемых чисел конечно, например: 0.0000; 0.0001; 0.0002; ...; 0.3960; 0.3961; 0.3962; ... Действительные числа образуют континуум -- непрерывное множество. Машинные числа приближенно соответствуют отображаемым числам: числа 0.0000145 и 0.396131 будут восприниматься ЭВМ как 0.0000 и 0.3961, то есть приближенно. Это приводит к следующему:
1. Строгие соотношения между действительными числами ![]() оказываются
нестрогими для их отображений
оказываются
нестрогими для их отображений ![]() : если
: если ![]() то
то ![]() .
.
2. Так как отображения действительных чисел являются приближенными, то математическая обработка действительных чисел в ЭВМ ведется с погрешностью.
3. Математическое понятие нуля заменяется понятием "машинный нуль", как значения, которое меньше некоторой определенной величины.
Число называется нормализованным в системе счисления ![]() , если оно
представлено в виде
, если оно
представлено в виде
![]() где
где ![]() -- мантисса,
лежащая в интервале
-- мантисса,
лежащая в интервале
![]()
![]() -- порядок числа.
-- порядок числа.
Пример. Представление чисел в нормализованном виде:
![]() в форме
чисел с фиксированной запятой:
в форме
чисел с фиксированной запятой:
![]()
Мантисса двоичного числа лежит в интервале
![]() ,
то есть содержит только цифры дробной части, которая всегда начинается
на 1. Поэтому ноль в разряде целых, запятую, отделяющую дробную часть,
и первую цифру дробной части мантиссы можно не сохранять, но восстанавливать
при вычислениях. Пример размещения числа
,
то есть содержит только цифры дробной части, которая всегда начинается
на 1. Поэтому ноль в разряде целых, запятую, отделяющую дробную часть,
и первую цифру дробной части мантиссы можно не сохранять, но восстанавливать
при вычислениях. Пример размещения числа
![]() в 32 разрядах:
в 32 разрядах:

Числа типа Real на языке Pascal размещаются 6 байтах, числа типа Extended занимают 10 байт.
1.7. Кодирование двоично-десятичных чисел.
Для вывода чисел на экран используется двоично-десятичное представление
чисел. В упакованном формате для каждой десятичной цифры отводится
по 4 двоичных разряда (полбайта), при этом знак числа
кодируется в крайнем правом полубайте числа (1100 -- знак
![]() и 1101 -- знак
и 1101 -- знак ![]() ).
).
При выполнении сложения и вычитания двоично-десятичных чисел
используется упакованный формат:
![]() Цифра
Цифра![]() Цифра
Цифра![]() Цифра
Цифра![]() Цифра
Цифра![]() Знак
Знак![]() .
Упакованный формат используется обычно в ПК при выполнении
операций сложения и вычитания двоично - десятичных чисел.
.
Упакованный формат используется обычно в ПК при выполнении
операций сложения и вычитания двоично - десятичных чисел.
В распакованном формате для каждой десятичной цифры отводится по целому байту, при этом старшие полубайты (зона) каждого байта (кроме самого младшего) в ЭВМ заполняются кодом 0011, а в младших (левых) полубайтах обычным образом кодируются десятичные цифры. Старший полубайт (зона) самого младшего (правого) байта используется для кодирования знака числа.
Структура поля упакованного формата:
![]() Зона
Зона![]() Цифра
Цифра![]() Зона
Зона![]() Знак
Знак![]() Цифра
Цифра![]()
Распакованный формат используется при вводе - выводе информации, а также при выполнении операций умножения и деления двоично-десятичных чисел.
Пример. Число
![]() имеет следующий
вид: а) в упакованном формате:
имеет следующий
вид: а) в упакованном формате:
![]() ,
б) в распакованном формате:
,
б) в распакованном формате:
![]() .
.
1.8. Кодирование команд. Машинная команда -- это элементарная инструкция, выполняемая ЭВМ автоматически без дополнительных указаний. Она состоит из двух частей: операционной и адресной.
В операционной части команды записан ее код, а в адресной -- один или несколько адресов ячеек памяти, в которых хранятся операнды (числа, участвующие в операции). Различают безадресные, одно-, двух-, трехадресные команды.
Команды могут кодироваться в двоичной, шестнадцатиричной и мнемонической (символической) формах. ЭВМ понимает только двоичную форму, при этом средняя по сложности программа состоит из тысяч битов. Для сокращения записи используют шестнадцатиричный код. Но это тоже не удобно: программист должен знать коды всех команд (около 100). Используется мнемонический (симоволический) код: каждая команда представлена совокупностью букв -- сокращений от английских названий команд. Симолическая программа транслируется ЭВМ в двоичный код и исполняется.
Структура трехадресной команды: ![]() КОП
КОП![]() где КОП -- код операции, A1, A2 -- адреса ячеек, содержащих
первый и второй операнды, A3 -- адрес ячейки,
куда следует поместить результат выполнения операции.
где КОП -- код операции, A1, A2 -- адреса ячеек, содержащих
первый и второй операнды, A3 -- адрес ячейки,
куда следует поместить результат выполнения операции.
Структура двух- и одноадресной команды: ![]() КОП
КОП![]()
![]() КОП
КОП![]() где
где ![]() -- адреса ячеек ОЗУ, где хранятся
операнды, и куда должен быть записан результат операции.
Безадресная команда содержит только код операции, а
информация для нее должна быть заранее помещена в
определенные ячейки памяти.
-- адреса ячеек ОЗУ, где хранятся
операнды, и куда должен быть записан результат операции.
Безадресная команда содержит только код операции, а
информация для нее должна быть заранее помещена в
определенные ячейки памяти.
Команда ![]() СЛ
СЛ![]() следует расшифровать так:
"сложить число, записанное в ячейке 0103 памяти, с числом, записанным в
ячейке 5102, а затем результат (то есть сумму) поместить в
ячейку 0103." Команды
следует расшифровать так:
"сложить число, записанное в ячейке 0103 памяти, с числом, записанным в
ячейке 5102, а затем результат (то есть сумму) поместить в
ячейку 0103." Команды ![]() и
и ![]() помещают
в регистр микропроцессорной памяти
помещают
в регистр микропроцессорной памяти
![]() содержимое ячейки
содержимое ячейки ![]() , после чего складывают содержимое регистров
, после чего складывают содержимое регистров
![]() и
и ![]() с последующей записью суммы в
с последующей записью суммы в ![]()
Все арифметические действия выполняются арифметико-логическим устройством. Сложение и вычитание чисел в двоично-десятичном представлении:
![]()
1.9. Кодирование текстовой информации.
Для представления текстовой информации используются 256 различных символов
(строчные и прописные буквы русского и латинского алфавитов, знаки препинания,
цифры и т.д.). Если считать, что использование каждого символа равновероятно,
то его информационный вес:
![]() бит
бит ![]() байт.
Для двоичного кодирования 1 символа требуется 1 байт (8 битов).
Тексты хранятся в памяти компьютера в двоичном коде и програмным способом
преобразуются в изображение на экране. В текстовом режиме экран разбит
на 25 строк по 80 символов в строке.
байт.
Для двоичного кодирования 1 символа требуется 1 байт (8 битов).
Тексты хранятся в памяти компьютера в двоичном коде и програмным способом
преобразуются в изображение на экране. В текстовом режиме экран разбит
на 25 строк по 80 символов в строке.
Информационный объем текстового сообщения в байтах численно
равен количеству символов ![]() В битах объем текстового файла
равен:
В битах объем текстового файла
равен: ![]()
1.10. Кодирование графической информации.
Форму представления на экране дисплея графического изображения, состоящего
из отдельных точек (пикселей), называют растровой.
Минимальным объектом в растровом графическом редакторе является точка
(пиксель -- picture element).
Разрешающая способность монитора (количество точек по горизонтали и
вертикали), а также число возможных цветов каждой точки определяются
типом монитора. Например: 640 ![]() 480= 307 200 точек,
800
480= 307 200 точек,
800 ![]() 600= 480 000 точек.
1 пиксель черно-белого экрана кодируется 1 битом информации.
Количество различных цветов
600= 480 000 точек.
1 пиксель черно-белого экрана кодируется 1 битом информации.
Количество различных цветов ![]() и битовая глубина (число разрядов,
используемых для кодировки цвета)
и битовая глубина (число разрядов,
используемых для кодировки цвета) ![]() связаны формулой:
связаны формулой: ![]()
Зависимость цветовой палитры монитора от информационной емкости одного пикселя: 4 бита -- 16 цветов, 8 бит -- 256 цветов.
Объем памяти, необходимой для хранения графического изображения, занимающего
весь экран, равен произведению количества пикселей (разрешающей способности)
на число бит, кодирующих одну точку.
Объем графического файла в битах определяется как произведение
количества пикселей ![]() на разрядность цвета (битовую глубину)
на разрядность цвета (битовую глубину)
![]()
Например, при разрешении ![]() и количестве цветов 16 (4 бита) объем памяти равен:
и количестве цветов 16 (4 бита) объем памяти равен:
![]() (бит) или
(бит) или
![]() Кбайт.
Кбайт.
Объемы видеопамяти для мониторов с различными разрешающей способностью и цветовой палитрой [1] представлены ниже.
| Бит/пиксель | 4 бита | 8 бит | 16 бит | 24 бита |
| Число цветов | |
|
|
|
|
640 |
150 Кбайт | 300 Кбайт | 600 Кбайт | 900 Кбайт |
|
800 |
234,4 Кбайт | 468,8 Кбайт | 937,6 Кбайт | 1,4 Мбайт |
|
1024 |
384 Кбайт | 768 Кбайт | 1,5 Мбайт | 2,25 Мбайт |
|
1280 |
640 Кбайт | 1,25 Мбайт | 2,5 Мбайт | 3,75 Мбайт |
Ввод и хранение в ЭВМ технических чертежей, состоящих из отрезков, дуг, окружностей осуществляется в векторной форме. Минимальной единицей, обрабатываемой векторным графическим редактором, является объект (прямоугольник, круг, дуга). Для каждой линии указывается ее тип: тонкая, штрихпунктирная и т.д. Хранение информации в векторной форме на несколько порядков сокращает необходимый объем памяти по сравнению с растровой.
1.11. Цифровое кодирование аналогового сигнала.
При оцифровке или дискретизации аналогового сигнала
![]() происходит замена непрерывной функции
происходит замена непрерывной функции ![]() на
интервале
на
интервале ![]() ломанной с большим количеством маленьких звеньев
(ступенек). Это осуществляется путем развертки по времени OCи квантования
по величине. Длительность ступенек равна шагу квантования по времени
ломанной с большим количеством маленьких звеньев
(ступенек). Это осуществляется путем развертки по времени OCи квантования
по величине. Длительность ступенек равна шагу квантования по времени
![]() , где
, где ![]() -- частота отсчетов, а их величина
кратна шагу квантования по величине
-- частота отсчетов, а их величина
кратна шагу квантования по величине ![]() Величина каждой
ступеньки представляется в двоичном коде, в результате чего
получается массив
Величина каждой
ступеньки представляется в двоичном коде, в результате чего
получается массив
![]() .
.
Теорема отсчетов В.А.Котельникова (1933 г.):
Непрерывный сигнал может быть оцифрован и воссоздан без потери информации,
если шаг развертки по времени не превышает половину периода максимальной
гармоники сигнала:
![]()
Например, для оцифровки речевого сигнала с частотой до 5 кГц, частота отсчетов долна быть не менее 10 кГц.
Теорема квантования по величине:
Для качественной оцифровки и воспроизведения непрерывного сигнала
достаточно, чтобы шаг квантования по величине ![]() был меньше чувствительности приемного устройства
был меньше чувствительности приемного устройства ![]() .
.
Если глаз человека (приемник) различает 16 миллионов цветовых оттенков, то при квантовании цвета не имеет смысла делать больше градаций.
Преимущества цифрового представления сигнала: высокая помехоустойчивость, универсальность, простота и надежность устройств, обрабатывающих информацию.
1.12. Кодирование звуковой информации.
Для записи и обработки аналогового сигнала с выхода микрофона
осуществляется его оцифровка с помощью аналого-цифрового преобразователя.
При этом они заменяются цифровыми
значениями отдельных выборок, взятых через достаточно короткие
промежутки времени ![]() То есть непрерывный сигнал
квантуется по величине и по времени, в результате чего
получается поток логических 0 и 1, которые обрабатывает процессор.
При 16-разрядном амплитудном кодировании непрерывный сигнал
разбивается на
То есть непрерывный сигнал
квантуется по величине и по времени, в результате чего
получается поток логических 0 и 1, которые обрабатывает процессор.
При 16-разрядном амплитудном кодировании непрерывный сигнал
разбивается на ![]() ступеней квантования. В соответствии с
теоремой отсчетов, частота квантования
44,1 кГц обеспечивает воспроизводимость всего звукового
диапазона частот (до 20 кГц). При этом объем файла в битах равен
ступеней квантования. В соответствии с
теоремой отсчетов, частота квантования
44,1 кГц обеспечивает воспроизводимость всего звукового
диапазона частот (до 20 кГц). При этом объем файла в битах равен
![]() где
где ![]() -- частота квантования,
-- частота квантования, ![]() --
разрядность квантования по величине (число ступенек),
--
разрядность квантования по величине (число ступенек), ![]() -- время записи.
Оцифрованный сигнал может быть преобразован в аналоговый
с помощью цифроаналогового преобразователя.
-- время записи.
Оцифрованный сигнал может быть преобразован в аналоговый
с помощью цифроаналогового преобразователя.
1.13. Кодирование видеоинформации.
Видеоинформация включает в себя последовательность кадров и звуковое
сопровождение. Так как объемом звуковой составляющей видеоклипа можно
пренебречь, то объем видеофайла примерно равен произведению количества
информации в каждом кадре на число кадров. Число кадров вычисляется
как произведение длительности видеоклипа ![]() на скорость кадров
на скорость кадров ![]() ,
то есть их количество в 1 с:
,
то есть их количество в 1 с:
![]() При разрешении 800*600 точек, разрядности цвета C=16, скорости кадров
v=25 кадров/c, видеоклип длительностью 30 с будет иметь объем:
При разрешении 800*600 точек, разрядности цвета C=16, скорости кадров
v=25 кадров/c, видеоклип длительностью 30 с будет иметь объем:
![]() бит
бит![]() байт
байт![]() Мбайт
Мбайт![]()
1.14. Аналоговое кодирование цифрового сигнала. Применяется при передаче данных по телефонным линиям связи и использует три способа модуляции:
1. Амплитудная модуляция: в соответствии с последовательностью передаваемых битов изменяется амплитуда синусоидальных колебаний, например, логической 1 соответствует большая амплитуда, а логическому 0 -- маленькая или отсутствие колебаний. OC
2. Частотная модуляция: в соответствии с передаваемыми битами изменяется частота колебаний: логическая 1 -- высокая частота, 0 -- низкая.
3. Фазовая модуляция: при переходе от логической 1 к логическому 0
и наоборот фаза колебаний изменяется на ![]()
1.15. Логические операции ЭВМ. Высказывание -- предложение, которое может быть истинным (логическая 1, true) или ложным (логический 0, false).
| УМНОЖЕНИЕ | СЛОЖЕНИЕ | СЛОЖЕНИЕ ПО mod2 | ИНВЕРСИЯ | ||
| A | B | A AND B | A OR B | A XOR B | NOT A |
| 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 | 0 |
Процессор ЭВМ состоит из логических элементов, выполняющих следующие
операции:
1) логическое сложение ИЛИ (дезъюнкция "+", A OR B);
2) логическое умножение И (конъюнкция "*", A AND B);
3) логическое сложение по ![]() (исключающее ИЛИ "
(исключающее ИЛИ "![]() ", A XOR B);
4) логическое отрицание НЕ (инверсия, NOT A).
", A XOR B);
4) логическое отрицание НЕ (инверсия, NOT A).
Перечисленные операции позволяют составить логические функции, которые
в зависимости от значений аргументов A, B, C принимают два значения:
истина (1) или ложь (0). Например:
![]() Каждой логической функции соответствует цепь из логических элементов.
Каждой логической функции соответствует цепь из логических элементов.
На основе логических элементов И, ИЛИ, НЕ построен процессор, осуществляющий математические и логические операции и управляющий работой ЭВМ, память ОЗУ, контроллеры и другие блоки ЭВМ.
1.16. Передача информации по сети. Информация, идущая от источника кодируется кодером и превращается преобразователем "коды-сигналы" в последовательность сигналов, поступающих в канал связи. Преобразователь "сигналы-коды" и декодер осуществляют обратное преобразование. На канал связи действуют шумы -- помехи, искажающие передаваемый сигнал, что компенсируется защитой от шумов.
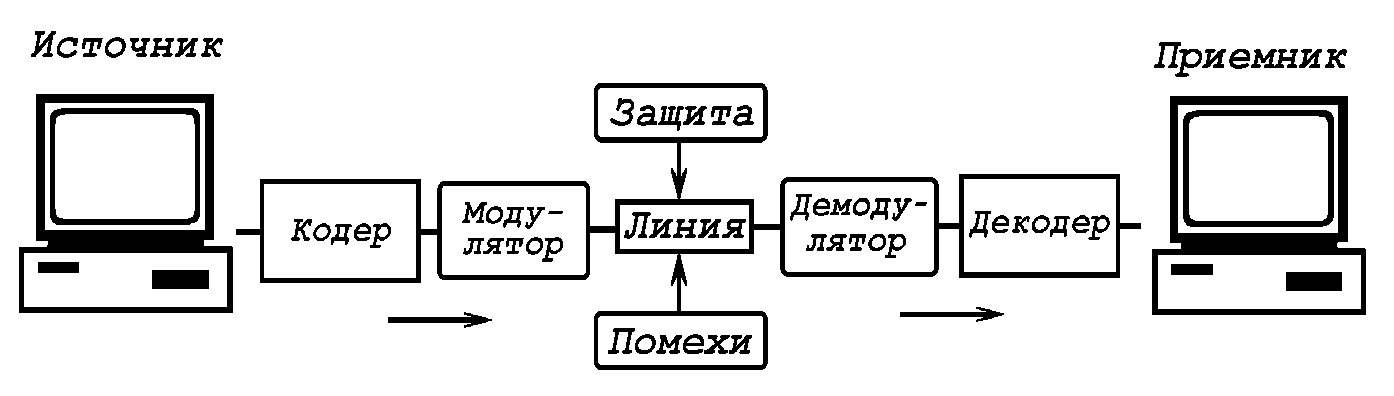
Первичным называется алфавит, используемый в сообщении,
которое выдает источник. Кодер преобразует сообщение, используя
вторичный алфавит. Пусть первичный алфавит ![]() содержит
содержит ![]() знаков, а вторичный
знаков, а вторичный ![]() --
-- ![]() знаков. На каждый знак первичного
и вторичного алфавита приходится средняя информация
знаков. На каждый знак первичного
и вторичного алфавита приходится средняя информация ![]() и
и ![]() .
.
Передаваемое сообщение в первичном алфавите содержит ![]() знаков,
а закодированное --
знаков,
а закодированное -- ![]() знаков, они несут количество информации
знаков, они несут количество информации
![]() и
и ![]() . Кодирование будет обратимым, при условии
неисчезновения информации, когда
. Кодирование будет обратимым, при условии
неисчезновения информации, когда ![]() , то есть количество
информации при обратимом кодировании не уменьшается. Тогда
, то есть количество
информации при обратимом кодировании не уменьшается. Тогда
![]() где
где ![]() -- длина кода, то есть
среднее число знаков вторичного алфавита
-- длина кода, то есть
среднее число знаков вторичного алфавита ![]() , используемых для
кодирования одного знака первичного алфавита
, используемых для
кодирования одного знака первичного алфавита ![]() Итак,
длина кода
Итак,
длина кода
![]() , а ее минимальное значение
, а ее минимальное значение
![]() Если
Если ![]() , то
, то ![]() , то есть одному знаку первичного
алфавита соответствует несколько знаков вторичного.
Относительная избыточность кода равна
, то есть одному знаку первичного
алфавита соответствует несколько знаков вторичного.
Относительная избыточность кода равна
Первая теорема Шеннона (основная теорема о кодировании при отсутствии помех): При отсутствии помех возможно кодирование, при котором избыточность кода будет сколь угодно близка к нулю.
Если вторичный алфавит имеет 2 знака (двоичный код), то в случае оптимального кодирования средняя длина двоичного кода должна быть равна среднему информационному содержанию знака первичного алфавита.
На реальный канал связи действуют помехи, в результате чего
возникают ошибки. Уровень достоверности передаваемого
сообщения может быть определен как отношение числа ошибок к
общему количеству знаков:
![]()
Вторая теорема Шеннона: Если скорость передачи не превышает попускной способности канала связи с шумом, то всегда найдется способ кодирования, при котором сообщение будет передаваться с требуемой достоверностью.
Возможны два способа решения проблемы: 1) способ кодирования только устанавливает факт искажения собщения, что позволяет потребовать повторную передачу; 2) используемый код находит и автоматически исправляет ошибку передачи.